1.6 内存组织和通信
到目前为止,我们只讨论了并行编程的执行问题,而在接触允许并行执行的硬件系统时,我们需要分析内存是如何组织的。
事实上,即使我们有一个功能强大、速度极快的中央处理器(CPU),并有许多处理单元(如内核),程序的性能也在很大程度上取决于内存的组织方式。
所有涉及向内存传输数据的操作一般都没有 CPU 的速度快,而且在这些操作过程中,内存一直被占用,直到内存周期结束,其他组件都无法使用内存。
与内存组织密切相关的一个概念是程序中各相关组件之间的通信。通信的形式与特定的内存组织密切相关,因此,并行程序的完美运行必须更好地管理进程和线程等执行实体之间的信息传递,而这要归功于内存。根据内存组织的不同,必须使用不同的机制来同步不同程序对象之间的信息传递,以避免数据不一致的风险或其他问题,如死锁和错误行为。
由此可见,内存对并行编程的性能起着非常重要的作用,因此,在我们的项目中对其行为进行评估非常重要。
1.6.1 进程内的内存组织
对于 Python 来说,程序中基本上有三种不同的内存组织模式:
- 令人尴尬的并行
- 共享内存
- 消息传递
第一种模式,令人尴尬的并行,指的是程序实体(无论是线程还是进程)不需要交换任何信息就能执行到底,并将单个结果合并在一起的特殊情况。事实上,有一些特殊的算法可以应对这种行为,它们被称为精确的令人尴尬的并行计算。
共享内存是 Python 中典型的线程内存组织模式。进程中的线程可以通过进程本身可用的共享内存相互通信。有几种可能的通信机制响应这种模型,有些有效,有些无效,我们将在本书中看到其中的一些。
另一方面,消息传递是进程的内存组织模型。事实上,这些进程没有共享内存,因此它们唯一的通信方式就是通过消息传递。对此有几种解决方案,通常以现成包的形式提供,称为消息传递接口 (MPI)。标准 Python 库本身就提供了一个 MPI 模块,专门用于这一任务。
1.6.2 多处理器之间的内存组织
到目前为止,我们一直在考虑单个多核 CPU 机器。但并行编程的现实自然延伸到多 CPU 的使用。这些处理器可能存在于一台机器上,也可能存在于以某种方式相互连接的不同机器上。
很明显,内存的组织也会对并行计算的完美运行产生影响。
前两种模式,即共享内存和消息传递,也以这两种模式的形式在这一领域得到了扩展:
- 共享内存
- 分布式内存
在采用共享内存模式的系统中,所有处理器都可以访问一个特定的内存区域,以共享数据和传递信息。这类系统通常基于物理总线,允许连接一定数量的物理上独立的处理器(但它们可以在同一台机器上,也可以在不同的机器上):
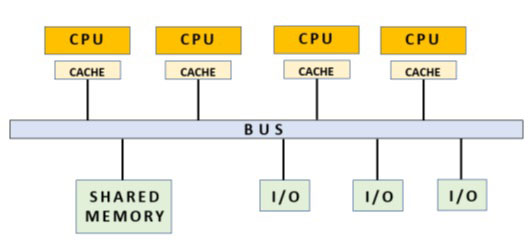
每个处理器都有自己的本地内存,由高速缓存表示,通常性能很高,因为 CPU 与该内存区域之间的数据交换非常频繁。但这一区域是有限的,而且各个处理器还经常需要共享工作数据,而这只能通过与总线相连的共享内存来实现。
这就是情况变得微妙的地方。程序员必须仔细管理各个处理器之间同时使用数据的同步问题。
其中一个 CPU 将从共享内存中获取数据值,并将其复制到缓存中,以某种方式进行处理。与此同时,另一个 CPU 将需要相同的值,它也会将共享内存中的数据复制到自己的缓存中。一段时间后,第一个 CPU 将完成处理,并将结果写入共享内存,更新其中的值。但在此期间,第二个 CPU 正在处理一个不再有效的值,因此这里的数据一致性已经丢失。因此,很明显,必须(通过硬件或编程)实施类似于单个进程内线程的并发管理机制和同步。
那么,为什么要使用这种模式呢?主要原因是共享内存系统非常快,因为它们主要依赖硬件而不是软件。事实上,CPU 访问共享内存资源的许多控制和同步机制都可以通过硬件来解决。
另一种模式是目前广泛使用的分布式内存模式。与前一种模式不同的是,连接各个 CPU 的不是物理总线,而是网络互连。事实上,这种模式主要用于物理上位于不同机器上的 CPU,即使它们之间的距离相当远。
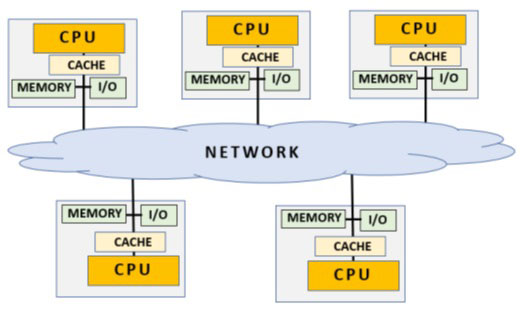
在这种模式下,每个 CPU 除了拥有自己的专用高速缓存外,还拥有一个本地内存,在正常情况下可以满负荷使用。当需要与其他 CPU 共享数据时,数据将通过网络发送。这样就不会再出现数据一致性问题,因为每个处理器都对自己的数据负责。另一个优点是,由于不再有物理总线,而只有网络连接,因此理论上可以在该系统中添加无限多的 CPU。
但这种模式的缺点是,网络连接的速度不如物理总线快,而且最重要的是,不同 CPU 之间的通信和数据交换需要一个消息传递机制。消息的管理,包括由各个 CPU 创建、发送和读取消息,一方面消除了一致性问题,但却大大降低了程序的执行速度。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
- https://wiki.python.org/moin/GlobalIntepreterLock
- https://www.udacity.com/blog/2020/04/what-is-python-parallelization.html
- https://www.infoworld.com/article/3542595/6-python-libraries-for-parallel-processing.html
- https://en.wikipedia.org/wiki/Monkey_patch
- https://greenlet.readthedocs.io
- https://www.koyeb.com/blog/introduction-to-synchronous-and-asynchronous-processing
- https://medium.com/fintechexplained/advanced-python-concurrency-and-parallelism-82e378f26ced
- https://sebastianraschka.com/Articles/2014_multiprocessing.html
- https://medium.com/fullstackai/concurrency-in-python-cooperative-vs-preemptive-scheduling-5feaed7f6e53
- https://carpentries-incubator.github.io/lesson-parallel-python/
- http://code.tutsplus.com/articles/introduction-to-parallel-and-concurrent-programming-in-python--cms-28612
- https://en.wikipedia.org/wiki/Speedup
- https://hpc-wiki.info/hpc/Scaling
- https://www.meccanismocomplesso.org/python/
1.7 分布式编程
分布式内存等复杂模型的存在进一步推动了并行编程的发展,以至于并行编程被定义为分布式编程。事实上,一个程序可以由连接到网络的不同机器上运行的不同进程并行执行。如今,这一系统已得到广泛应用,以至于有许多 Python 软件包都提供了这方面的解决方案。在本书中,我们还将使用网络上免费提供的一些软件包来处理并行编程的这一进一步扩展,并专门用一整章来介绍它们,即第 5 章 “使用分布式系统实现并行性”。
1.8 并行编程的评估
当你决定使用并行技术时,是因为你需要在尽可能短的时间内解决大问题。然而,要实现这一目标,需要考虑许多因素,如并行程度、硬件,尤其是编程模型。因此,有必要进行性能分析,以评估我们在程序开发过程中所做选择的正确性。
有一系列性能指标可以通过评估其数值来衡量程序的性能。这些指数不过是通过适当计算获得的数值,可以让我们以系统、精确的方式对程序或算法进行比较。在这些指数中,最著名和最常用的是加速度。
1.8.1 加速比
加速度是一个数字,表示运行相同问题的两个系统之间的性能差异。在我们的例子中,加速度 S 可视为执行串行程序 ts 所花费的时间与我们创建的并行程序执行相同操作所花费的时间 tp 之间的比率。所用时间 t 是处理单元 N 数量的函数,处理单元可以是 CPU、内核或 GPU,但 N 通常指处理器的数量。因此,并行系统的耗时可以用 t(N)来表示,而串行系统的耗时则可以用 t(1)来表示,因为串行系统相当于只有一个处理器的系统:
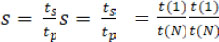
换句话说,加速度让我们了解到采用并行解法与串行解法相比在性能上的优势。此外,如果将 N 个处理器的数量与提速指数进行比较,我们还可以进一步对算法或程序进行分类:
- 如果 S = N,则加速是线性或理想的
- 如果 S <N,则加速为实际加速
- 如果 S> N,则为超线性加速比
加速指数还与并行计算中广泛使用的阿姆达尔定律有关。该定律用于预测程序在使用无限处理器时所能达到的最大加速度。它描述了程序中串行代码的百分比如何决定可实现的最大加速值:
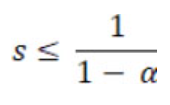
其中,S 是加速指数,α 是程序中并行执行的部分所占用的时间。
因此,如果我们有一个程序,并行运行代码需要 90 分钟,串行运行代码需要 10 分钟,总计 100 分钟,那么 α = 0.9。因此,在这种情况下,可获得的最大提速将是
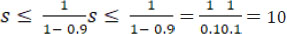
我们的程序可获得的最大速度提升将是 10。通过逐步增加执行内核或处理器,我们将逐步提高程序的性能,直到速度接近 10。一旦达到这个值,即使我们增加更多的处理器或内核来并行运行,也不会有进一步的提高。
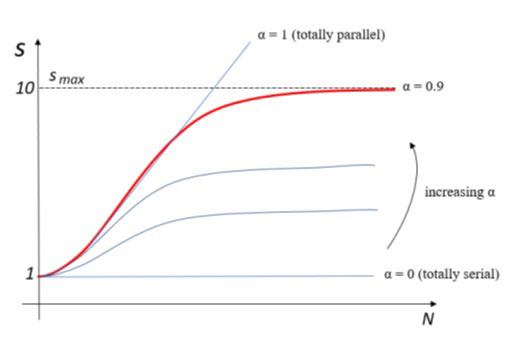
因此,如果我们想不断提高程序或算法的速度,就必须尽可能减少串行代码部分。只有这样,通过增加处理器(或内核)的数量,我们才能不断提高性能。
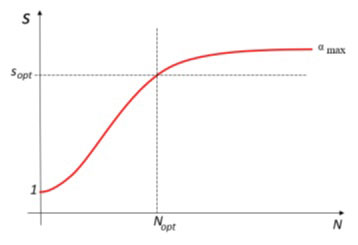
此外,一旦代码的可并行化部分达到最大化,接下来的任务就是找到合适的折中方案,即在使用正确数量的处理器的情况下尽可能提高速度。这样可以避免因增加过多处理器而导致不必要的并行工作负载:
1.8.2 扩展(Scaling 又名缩放)
扩展是指系统通过增加硬件(处理器数量)来提高计算效率的能力。在并行计算中,扩展指的是并行化效率,即随着所用处理器数量的增加,实际速度与理想速度之间的比率。
扩展可分为两种类型:
- 强扩展
- 弱扩展
当处理器数量增加而问题规模保持不变时,就会出现强扩展。在理想情况下,这会导致每个处理器的工作量日益减少。
弱扩展是指处理器数量随着处理器规模的增加而增加。在这种情况下,每个处理器的工作量应保持不变。
通过应用阿姆达尔定律,我们看到了一个强大的扩展措施,即通过保持问题大小不变和增加处理器数量来计算加速度。在这种情况下,该定律已经向我们表明,由于不可能对 100% 的代码进行并行化处理,速度提升仍有最大限度。此外,还有许多其他因素在起作用,这使得随着处理器数量的增加,保持良好的强扩展性变得越来越困难。例如,后者的数量不断增加,就需要不断增加相互通信所需的工作量。
至于弱扩展,这种情况下的速度提升没有最大上限,因此可以无限增长(理论上)。古斯塔夫森定律证实了这一点,该定律对加速计算的定义与阿姆达尔定律不同:
S = (1 - α) + α * N
事实上,古斯塔夫森感觉到,随着问题规模的增大,只有代码并行部分 α 的加速度随着处理器数量的增加而增加,而串行部分 (1- α) 的加速度却没有增加。
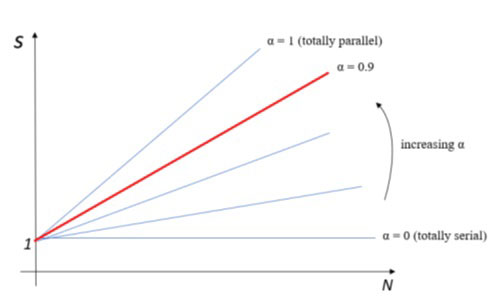
借助强扩展和弱扩展的概念以及 Amdahl 和 Gustafson 的两个定律,我们可以得出一些有用的结论:对于小问题,最好使用小系统;对于大问题,最好使用大系统。
1.8.3 Python中的基准测试
在不同条件下系统地测试性能的行为称为基准测试。到目前为止,我们已经从理论角度对程序的性能进行了评估。但从实践的角度来看呢?在 Python 中有一系列工具可以让我们测量程序或代码的性能。
在接下来的章节中,我们将看到一些如何进行这些测量的实际例子。例如,我们将使用标准 Python 库中的时间模块来计算执行一段代码所花费的时间(也可用于计算加速度)。该模块可以访问多种类型的时钟,通过调用 time() 方法,我们可以获得真实的秒表读数。然后,通过对读取的时间进行差分,我们将获得两次调用之间包含的代码所花费的时间:
started = time.time()
# Code here
elapsed = time.time()
print(“Elapsed time=”, elapsed - started)
1.8.4 剖析(Profiling)
分析程序的哪些部分对性能有贡献,并找出任何瓶颈,这就是剖析。
在 Python 中,目前有几种这方面的工具,每种工具都有自己的特点。关于内存资源的消耗,可以使用一个强大的工具:包内存剖析器。该模块可以监控 Python 中不同进程/任务的内存消耗。此外,它还可以逐行分析代码的资源消耗情况,因此也可以作为行剖析器使用。
1.9 结论
本章详细讨论了并行编程的大部分基本概念。随着时间的推移,并行编程与现有技术同步发展,共享逐渐形成的概念和实体。在并行编程中,运行在操作系统中的进程和线程可以使用进程和线程对象进行匹配,这些对象可以使用标准 Python 库中的线程和多处理模块来实现。在接下来的两章中,我们将了解如何使用这两个模块进行并行编程,并充分利用它们提供的所有功能。
需要记住的要点
- 并发性: 这意味着同时管理多个任务,但它们不一定同时运行。
- 并行性: 即同时运行多个任务。
- 线程: Python 中的线程不能并发运行,因此不能并行操作。